Pooling
Pooling is a technique used to efficiently reduce dimensionality, and therefore complexity and computation.
It involves sectioning off your original image and applying some reductive function to the values in those cells. Just like convolution, we can set filter size and stride hyperparameters to adjust the output size.
Example: Applying np.max() to the values
from IPython.display import Image
Image('images/pooling.png')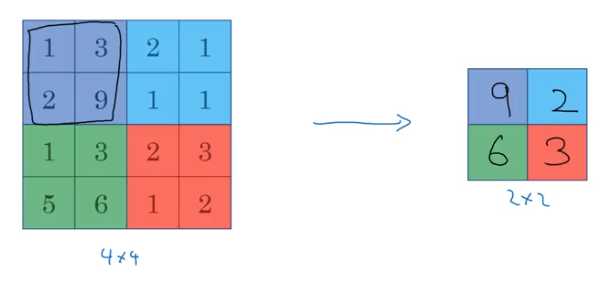
Max Pooling is the preferred method over any other calculation (e.g. average).
And as a nice side-effect to this, there’s no parameters to learn to teach the network “how to take the max of something”– this is wholesale a helpful dimensionality-reduction technique.
Translation Invariance
Recall that the convolution operation is comprised of two things:
- A sliding operator, local to different areas in an image
- An element-wise product and sum over that area
Because the sum isn’t all-or-nothing, you may apply a filter to a section of an image to different results, depending on how much of your area of interest is caught by the filter. For instance
1 3 1
2 8 2
1 3 1
In this example, if you were max pooling over a 3x3 area, it wouldn’t matter if your image was translated a bit in any direction, because the 8 value would still be in the same maximum value for this filter.
Translation Tolerance Across Layers
Typically, when we think about size and convolution, we think about shrinking and dimensionality reduction.
However, take a minute to start at the end and consider how much of the original image (as a percentage of area) informs activations in the later layers.
from IPython.display import Image
Image('images/translation_tolerance.png')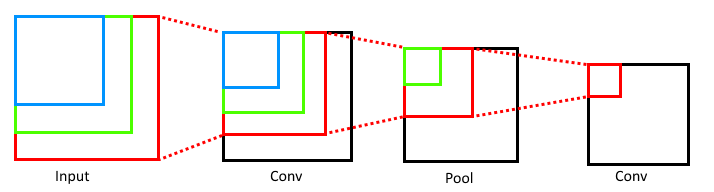
This illustration should help reinforce some intuition that the deeper the convolutional layer, the more of the original image is considered.
Therefore, as a simple example, if you had a cat-image classifier, your early feature detectors (edges, hue shifts, etc) would span the entire image, but regardless of where the cat was in the image, the later layers would combine earlier features appropriately.